Enviando Logs para o S3 com o Vector
Recentemente fiz um POC visando analisar uma alternativa para fazer o stream de logs imutáveis do sistema e aplicações para um bucket, fazendo uso das features de gerenciamento de ciclo de vida de objetos, migrando entre storage classes e implementando políticas de retenção mínima, expiração (para deleção automática após um determinado período) e bloqueio de exclusão ou alteração dos objetos, enquanto contemplarem o período de retenção.
O legal é que os dois Cloud providers que analisei (AWS e GCP) possuem uma forma relativamente simples de fazer essa gestão de ciclo de vida dos objetos armazenados no Bucket. E como esse não é o foco do post, deixo os links para compreender melhor o funcionamento dessas funcionalidades.
- AWS - Object lifecycle management
- AWS - Understanding object expiration
- AWS - Transitioning objects using Amazon S3 Lifecycle
- GCP - Práticas recomendadas do Cloud Storage
- GCP - Classes de armazenamento
- GCP - Políticas de retenção e bloqueios
- GCP - Gerenciamento do ciclo de vida de objetos
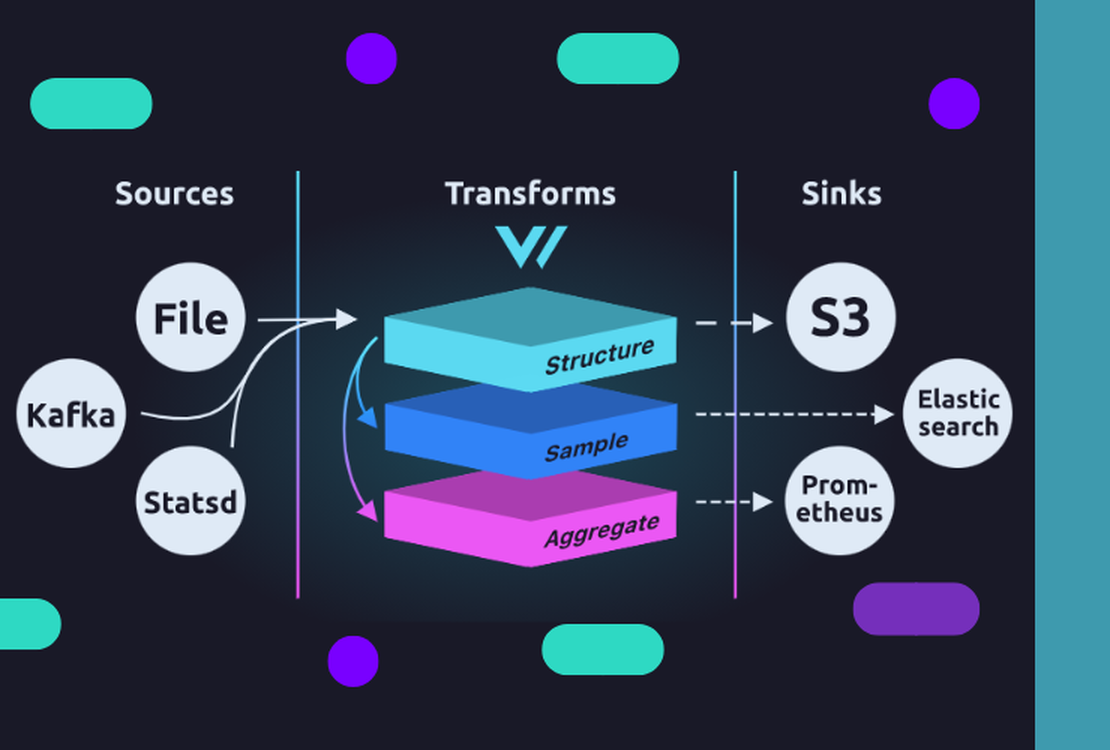
O que é o Vector?
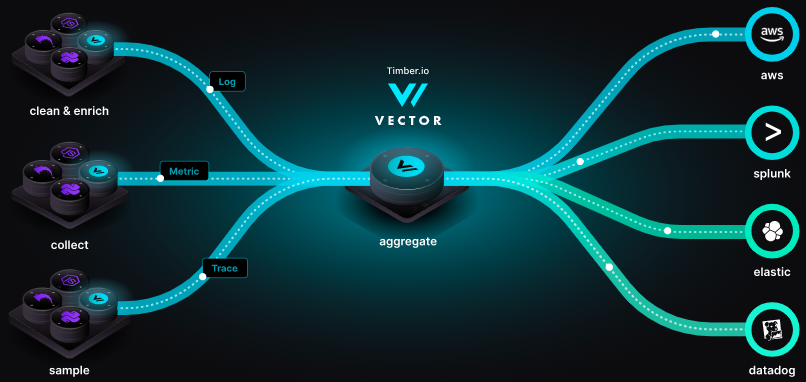
Diagrama Vector
O Vector é uma ferramenta leve e ultrarrápida, escrita em Rust que possibilita construir pipelines de observabilidade de uma maneira fácil e efetiva. Ele tem como principal objetivo fazer com que você assuma o controle de seus dados de observabilidade, coletando, transformando e roteando todos os dados com uma ferramenta simples.
Porque o Vector?
Sempre digo que tudo depende do projeto, devemos analisar quais as características do ambiente, finalidade, e principalmente o melhor custo computacional, seja de recursos de CPU, RAM, IO ou tráfego. Tudo é relativo e deve ser analisado caso a caso. Não é porque você manja muito de uma determinada ferramenta, ou ela é a “ferramenta da moda”, que essa vai ser a melhor escolha para o seu projeto.
Para este projeto, uma das principais vantagens em relação a outras alternativas era a alta capacidade de analisar entradas de dados em arquivos texto e enviar esses dados via TCP para um bucket. Imagine um NGINX com milhares de requisições por segundo. O Vector se sai muito bem nesse contexto, que podemos validar no gráfico abaixo:
Note
Todos os gráficos são relacionados a leitura de arquivos de log e envio TCP, sem transformação. Lembre-se que o intuito é enviar logs imutáveis ao S3. :wink:
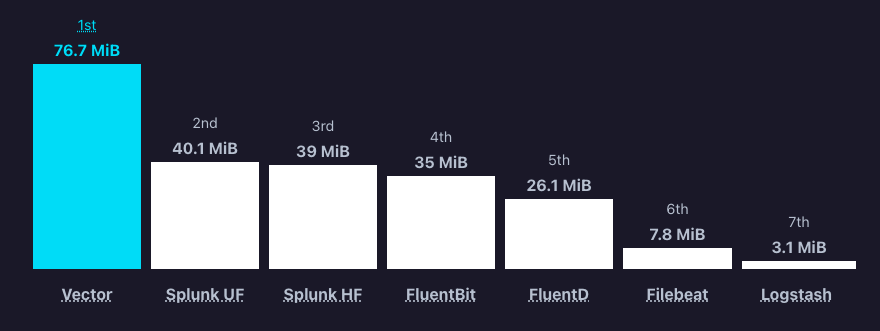
Gráfico Vector - Arquivos para TCP
Somado a isso, a baixa utilização de memória foi outra questão que chamou bastante atenção. O que era uma das principais métricas a analisar, tendo em vista a alta demanda de entrada de logs devido a característica das aplicações. Podemos validar isso no gráfico de utilização de RAM:
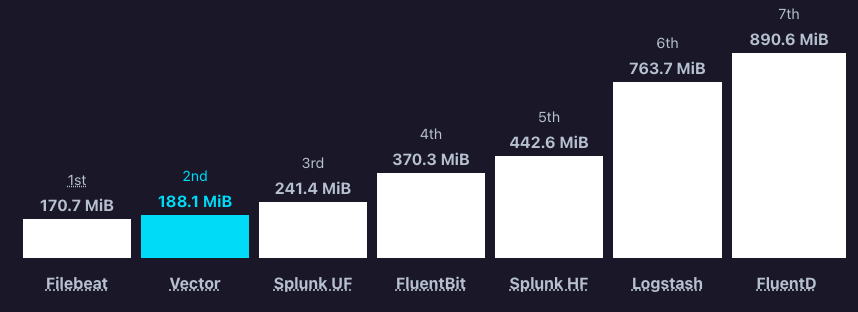
Gráfico Vector - Utilização de RAM
Se podemos dizer alguma coisa em que o Vector não se sai tão bem quando olhando nos gráficos, é na questão da utilização de CPU, mas isso é subjetivo, o valor referenciado no gráfico é extremamente baixo, principalmente quando você analiza o poder de processamento e envio de dados via stream TCP. No conjunto ele se sai muito melhor.
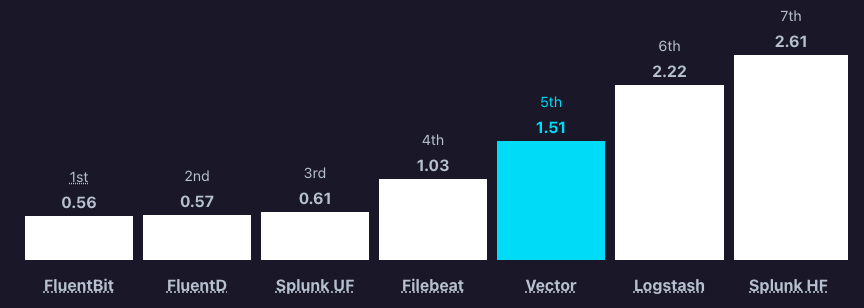
Gráfico Vector - Utilização de CPU
Enviando logs para o S3
O processo é bem simples, basta escolher a forma de utilização do agente e carregar as configurações. Eu prefiro separar um arquivo com as configurações genéricas, e outros com o pipeline de cada aplicação, por exemplo, logs do messages, secure, dmesg, nginx, etc. Mas para facilitar, irei deixar tudo em um arquivo, o principal que geralmente fica em /etc/vector/vector.toml.
Recomendo verificar os mais variados métodos de instalação na própria documentação.
Vale ressaltar que o Vector utiliza os já conhecidos métodos de autenticação no S3. Mas caso queira analisar melhor as alternativas, recomendo ler a documentação.
Configuração do pipeline
data_dir = "/var/lib/vector" # crie o diretório caso não exista
[[sources.messages]
type = "file"
include = ["/var/log/messages"] # arquivo a ser monitorado
ignore_older = 86400 # ignora entradas com mais de 1 dia
[sinks.s3_messages]
type = "aws_s3"
inputs = ["messages"]
bucket = "nome-do-seu-bucket"
compression = "gzip" # salva os arquivos compactados no bucket
region = "us-east-1" # região do seu bucket
# Batch
batch.max_bytes = 10000000 # tamanho máximo do batch a ser enviado para o S3
batch.timeout_secs = 300 # caso não atinja o tamanho máximo, no tempo aqui definido ele envia o buffer para o S3
# Encoding
encoding.codec = "ndjson"
# File Naming
filename_append_uuid = false # optional, default
filename_extension = "gz" # optional, default
filename_time_format = "%Y%m%d%H%M%S"
# File Naming
key_prefix = "${HOSTNAME}/messages/%Y/%m/%d/" #Aqui é para definir o padrão de armazenamento na estrutura do bucket.
E não é nada além disso, quando estiver rodando, a estrutura no bucket será algo como:
-- vector.finardi.me #nome do host
|-- messages # nome da aplicação/log
| `-- 2021 # ano
| `-- 01 # mês
| |-- 28 # dia
| | |-- 20210128210109.gz # log gerado
| | `-- 20210128230246.gz
| `-- 29
| `-- 20210129122451.gz
Conclusão
O Vector se mostrou uma poderosa ferramenta para construção de pipelines de observabilidade, ainda mais nessa questão de armazenar logs imutáveis em um bucket com definição de ciclo de vida, retenção e remoção automática do objeto após a data de expiração. Vale muito a pena analisar esta ferramenta em seus projetos.